What supervision actually means
"Human-in-the-loop" has become a marketing phrase. What we mean by supervision is narrower and more specific: a lawyer or legal ops professional retains final authority over every piece of work the agent produces, but only intervenes where the agent is uncertain, the matter is novel, or the policy says so.
The word does a lot of work in this market, so it's worth being precise. There are at least three things people mean when they say "supervised AI" — and only one of them is what Flank is.
"If a supervisor is reading every redline before it goes out, how is this different from me doing the work myself?" Short answer: in week one, it isn't very different. The point is what happens in weeks four, twelve, and twenty-four — and whether the system is designed to get you there.
The four things a supervisor does
In a mature Flank deployment, a supervisor's job collapses to four discrete activities. Everything else the agent handles itself.
Notice what's not on this list: drafting, reviewing full documents, chasing the business for information, logging outcomes, following up on signatures. The agent does all of that. A supervisor's attention is the scarcest resource in the system, and the system is built to spend it only where it matters.
Week by week: from day one to mature deployment
The most honest thing we can say about supervision is that it is heavier at the start than it will be later. Prospects who expect day-one autonomy are disappointed. Prospects who brace for a permanent line-by-line review burden are surprised — usually by week four, sometimes earlier.
Figures are typical for a mid-market NDA / MSA flow across Flank customers. Higher-stakes commercial matters and regulated workflows converge more slowly.
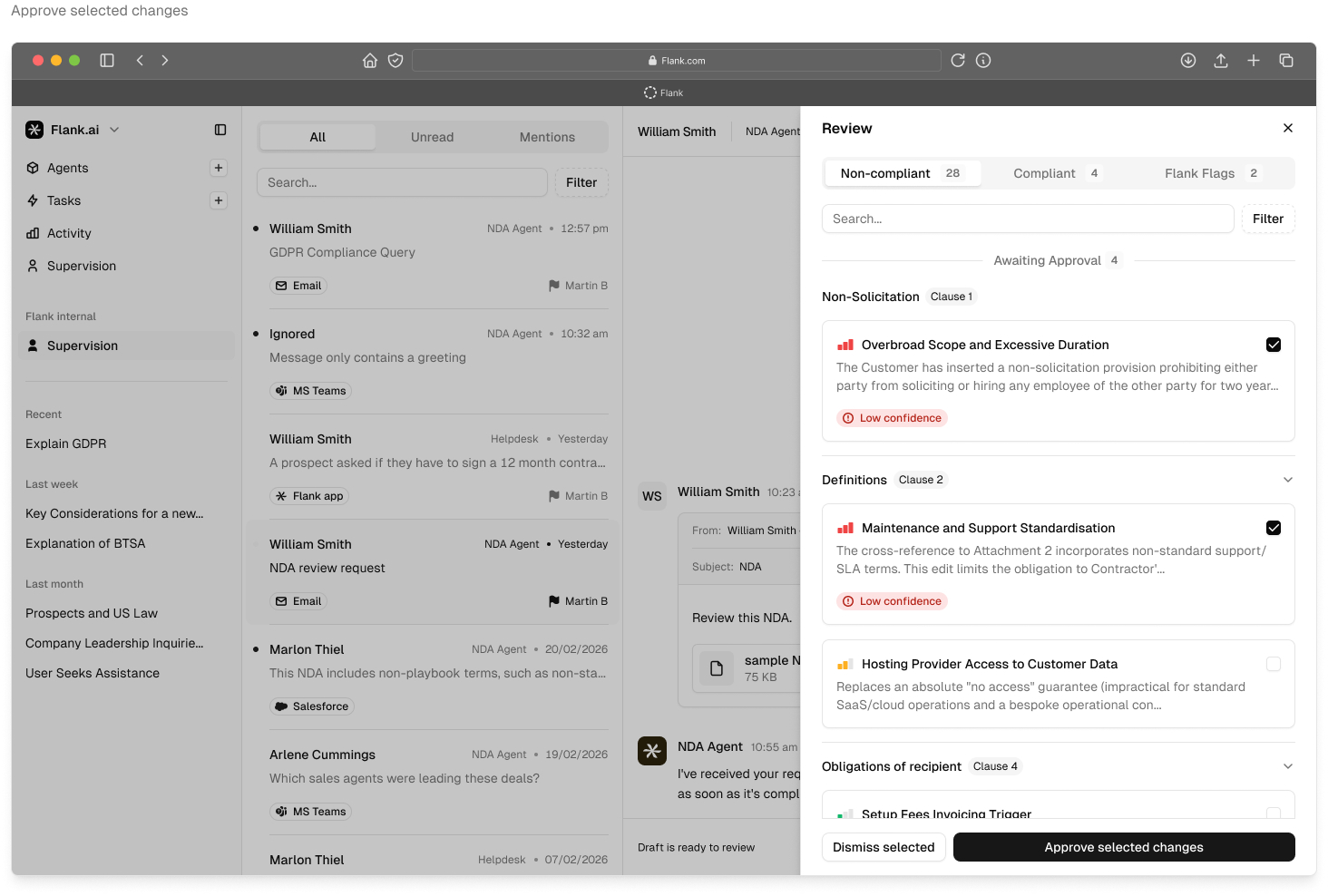
Risk-based approval and confidence scoring
The curve in the previous section is not the result of the model getting smarter week over week. It's the result of a workflow that grades every output on two axes — confidence and risk — and uses the grade to decide what reaches a human.
Confidence alone isn't enough. A high-confidence output on a bet-the-company indemnity still warrants a human look; a medium-confidence output on a standard governing-law clause does not. The two axes combine into a risk-based approval matrix that decides, per output, whether it auto-approves, escalates to the agent's own second pass, flags for supervisor review, or goes straight to a named escalation.
In the product, every flagged clause carries a visible reason. The agent surfaces the playbook position it's comparing against ("The playbook maximum is 12 months"), drafts the proposed redline with a diff view (strikethrough in red, replacement in green), and reduces the human decision to a single dismiss / confirm choice — or, where confidence is high enough to justify it, handles the clause silently and reports it in the auto-confirmed lane.
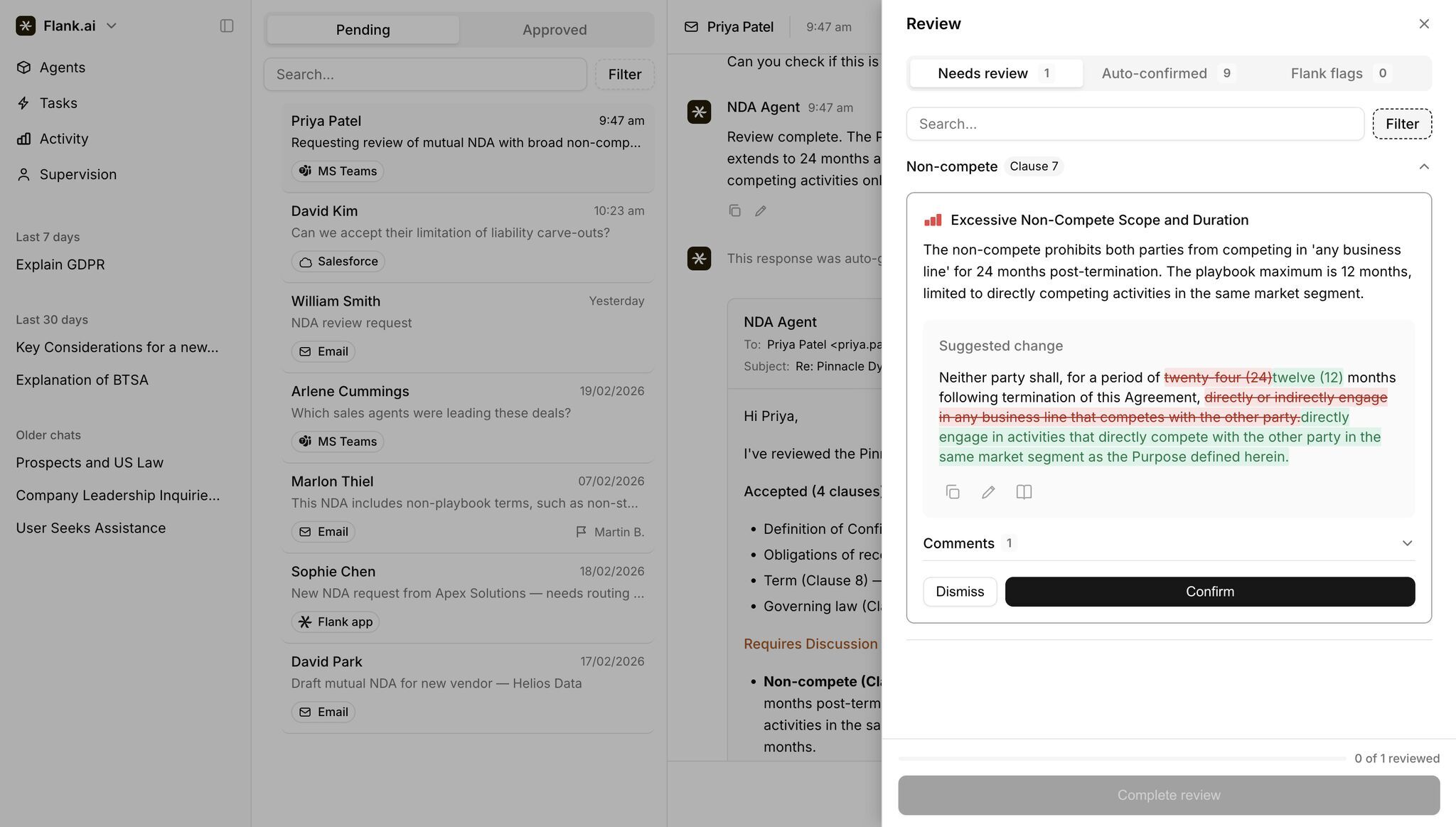
The Review panel reads "Needs review 1 · Auto-confirmed 9 · Flank flags 0." Nine clauses out of ten passed through without a supervisor touching them. The one that didn't arrives pre-diagnosed and pre-drafted — all the human has to do is look, think, and click. That ratio, and the shape of what reaches the queue, is the whole product.
How the thresholds are set
The thresholds that govern "what gets escalated" are not set by Flank. They're set by the customer during sprint zero and tuned across the first month of deployment. A conservative team can dial up escalation on day one, then relax it as trust builds. A more aggressive team can run with lower thresholds from the start. Either way, the supervisor is in control of the tap.
| Risk tier | Typical threshold | Who sees it |
|---|---|---|
| Low — standard clauses | Auto-approve if confidence > 90% | No human unless flagged |
| Medium — fallback positions | Auto-approve if confidence > 95% and inside playbook | Legal ops spot-check |
| High — commercial terms | Always flag for review | Supervising lawyer |
| Critical — custom / bet-the-company | Never auto-handled | Named escalation |
Line-by-line review is a symptom, not the job
One of the most common things we hear from teams mid-pilot is some version of: "my supervisors are doing line-by-line review that takes almost as long as doing the work themselves." Almost always, this is a signal that the setup is still in its first three weeks — and that the playbook, thresholds, or escalation rules need tuning, not that supervision itself is broken.
The discomfort in the first three weeks is real, and we don't hide it from prospects. The question any evaluator should ask isn't "how much supervision will I have to do?" — it's "is the system designed to reduce the supervision workload over time, and is there evidence it actually does?" The answer to both should be yes, with data to back it up.
If your supervision workload isn't dropping meaningfully between week one and week four, something is wrong with the setup, not with the concept. Playbooks too thin, thresholds mistuned, or the work doesn't actually fit the agent yet. In every case, the fix is visible in the data — which is why we run a weekly review across the first eight weeks of every deployment.
Who supervises what
Supervision is not a single job. In most deployments, the work splits across three roles that already exist in the legal team — lawyers, legal ops, and legal admin. The agent routes each class of exception to the role best placed to handle it.
| Role | Supervises | Typical time commitment |
|---|---|---|
| Lawyer | Commercial terms, legal exceptions, novel counterparty positions, escalations that touch risk or strategy. | ~30 min/day at steady state. Concentrated on high-value judgement calls, not volume. |
| Legal ops | Playbook maintenance, threshold tuning, weekly metrics review, exception patterns, integration health. | ~2–3 hours/week. Treats the agent like any other operational system under their remit. |
| Legal admin / paralegal | Low-risk procedural checks, counterparty data validation, signature routing, internal stakeholder follow-ups the agent flags for a human touch. | ~1 hour/day. Much of this work simply wasn't happening reliably before. |
The important point: no role is doing work beneath its seniority. The lawyer is not reading NDAs line by line. The legal ops lead is not chasing counterparty signatures. The admin is not making commercial judgement calls. This separation is the whole point, and it's what collapses when teams try to wrap a base model themselves and end up with one person approving everything the model produces.
What "supervised to near-zero error" looks like
Accuracy metrics in isolation mislead. A 93% accurate agent sounds worrying; a 93% accurate agent behind a well-tuned supervision layer is, in production, closer to 99.5% — because the 7% the agent gets wrong is disproportionately the 7% it's least confident about, which is disproportionately what gets escalated to a human.
Supervision is not a tax you pay on agent inaccuracy. It's the mechanism that converts model accuracy into system reliability. The raw model output is the floor. The supervised output is the ceiling. The gap between the two is where the product actually lives.
What we track, and what we share with customers
Every supervised action is logged against the counterfactual — would a human reviewer have caught what the agent caught, would they have flagged what the agent flagged, would they have drafted the redline the agent drafted. Every week of a deployment produces a supervision quality report covering:
- Confidence calibration — does 90% confidence actually mean 90% correct?
- Escalation rate by contract type and risk tier
- Playbook coverage — what fraction of outputs fall inside the playbook vs novel
- Redline acceptance rate from counterparties
- Supervisor override rate — how often humans disagree with the agent
- Median review time per flagged output
- Escalation-to-resolution latency
- Drift markers — are override rates trending up or down over time?
Day one vs. month three
The clearest way to describe the supervision experience is to contrast it with itself. Here's what the same legal team looks like at two points in the same deployment.
- Supervisor reviews ~90% of outputs end-to-end
- Playbook captures the team's most common positions but has gaps
- Escalation thresholds intentionally conservative
- Confidence calibration still being verified against human ground truth
- Weekly review meeting with Flank is dense — lots of playbook edits
- Time spent per contract: comparable to doing the work manually
- Team still sceptical; waiting for evidence
- Supervisor reviews <5% of outputs — only genuine exceptions
- Playbook is well-developed, covering edge cases as they've been resolved
- Escalation thresholds tuned to the team's actual risk tolerance
- Confidence scores well-calibrated against months of override data
- Weekly review is light — mostly metrics and drift checks
- Time spent per contract: minutes, for the small fraction that needs it
- Team is using freed time for work that was previously deferred
This is not an aspirational before-and-after. It's the pattern we see across deployments, roughly on this timeline, when the setup is done properly and the supervisor is engaged in the first month. The deployments that don't resolve like this are the ones where the playbook never gets tuned, or the thresholds are set once and never revisited, or supervision is treated as a one-off project instead of a weekly discipline.
If you're evaluating Flank or any other agentic legal service, don't ask "how accurate is it?" — ask "what does supervision look like in week one, week four, and month three, and can you show me the data for a customer at each stage?" The answer will tell you whether you're buying a tool or a service, and whether the curve actually exists in their deployments.